
Memory Hierarchy Design PowerPoint PPT Presentation
Title: Memory Hierarchy Design
1
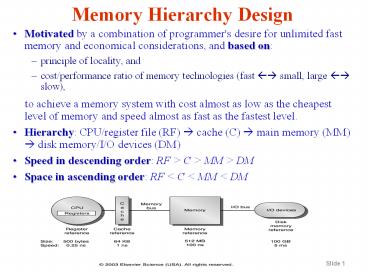
Memory Hierarchy Design
- Motivated by a combination of programmer's desire
for unlimited fast memory and economical
considerations, and based on - principle of locality, and
- cost/performance ratio of memory technologies
(fast ?? small, large ?? slow), - to achieve a memory system with cost almost
as low as the cheapest level of memory and speed
almost as fast as the fastest level. - Hierarchy CPU/register file (RF) ? cache (C) ?
main memory (MM) ? disk memory/I/O devices (DM) - Speed in descending order RF gt C gt MM gt DM
- Space in ascending order RF lt C lt MM lt DM
2
Memory Hierarchy Design
- The gaps in speed and space between the different
levels are widening increasingly
Level/Name 1/RF 2/C 3/MM 4/DM
Typical size lt 1 KB lt 16 MB lt 16 GB gt 100GB
Implementation technology Custom memory w. multiple ports, CMOS On-chip or off-chip CMOS SRAM CMOS DRAM Magnetic disk
Access time (ns) 0.25-0.5 0.5-25 80-250 5,000,000
Bandwidth 20,000-100,000 (MB/s) 5000-10,000 (MB/s) 1000-5000 (MB/s) 20-150 (MB/s)
Managed by Compiler Hardware Operating system OS/operator
Backed by Cache Main memory Disk CD or tape
3
Memory Hierarchy Design
- Cache performance review
- Memory stall cycles Number_of_misses
Miss_penalty - IC
Miss_per_instr Miss_penalty - IC
MAPI Miss_rate Miss_penalty - where MAPI stands for memory accesses
per instruction - Four Fundamental Memory Hierarchy Design Issues
- Block placement issue where can a block, the
atomic memory unit in cache-memory transactions,
be placed in the upper level? - Block identification issue how is a block found
if it is in the upper level? - Block replacement issue which block should be
replaced on a miss? - Write strategy issue what happens on a write?
4
Memory Hierarchy Design
- Placement three approaches
- fully associative any block in the main memory
can be placed in any block frame. It is flexible
but expensive due to associativity - direct mapping each block in memory is placed in
a fixed block frame with the following mapping
function (Block Address) MOD (Number of blocks
in cache) - set associative a compromise between fully
associative and direct mapping The cache is
divided into sets of block frames, and each block
from the memory is first mapped to a fixed set
wherein the block can be placed in any block
frame. Mapping to a set follows the function,
called a bit selection - (Block Address) MOD
(Number of sets in cache)
5
Memory Hierarchy Design
- Identification
- Each block frame in the cache has an address tag
indicating the block's address in the memory - All possible tags are searched in parallel
- A valid bit is attached to the tag to indicate
whether the block contains valid information or
not - An address for a datum from CPU, A, is divided
into a block address field and a block offset
field - block address (A) / (block size)
- block offset (A) MOD (block size)
- block address is further divided into tag and
index - index indicates the set in which the block may
reside - tag is compared to indicate a hit or a miss
6
Memory Hierarchy Design
- Replacement on a cache miss
- The more choices for replacement, the more
expensive for hardware ? direct mapping is the
simplest - Random vs. least-recently used (LRU) the former
has uniform allocation and is simple to build
while the latter can take advantage of temporal
locality but can be expensive to implement
(why?). First in, first out (FIFO) approximates
LRU and is simpler than LRU - Data cache misses per 1000
instructions
Associativity Associativity Associativity Associativity Associativity Associativity Associativity Associativity Associativity
Two-way Two-way Two-way Four-way Four-way Four-way Eight-way Eight-way Eight-way
Size LUR Random FIFO LUR Random FIFO LUR Random FIFO
16K 114.1 117.3 115.5 111.7 115.1 113.3 109.0 111.8 110.4
64K 103.4 104.3 103.9 102.4 102.3 103.1 99.7 100.5 100.3
256K 92.2 92.1 92.5 92.1 92.1 92.5 92.1 92.1 92.5
7
Memory Hierarchy Design
- Write strategies
- Most cache accesses are reads 10 stores 37
loads 100 instructions ? only 7 of all memory
accesses are writes - Optimize reads to make the common case fast,
observing that CPU doesn't have to wait for
writes while must wait for reads fortunately,
read is easy in direct-mapping reading and tag
comparison can be done in parallel (what about
associative mapping?) but write is hard - Cannot overlap tag reading and block writing
(destructive) - CPU specifies write size only 1 - 8 bytes. Thus
write strategies often distinguish cache design
On a write hit - write through (or store through)
- ensuring consistency at the cost of memory and
bus bandwidth - write stalls may be alleviated by using write
buffers - write back (store in)
- minimizing memory and bus traffic at the cost of
weakened consistency, - use dirty bit to indicate modification
- read misses may result in writes (why?)
- On a write miss
- write allocate (fetch on write)
- no-write allocate (write around)
8
Memory Hierarchy Design
- An ExampleThe Alpha 21264 Data Cache
- Cache size64KB, block size64B, two-way set
associativity, write-back, write allocate on a
write miss. - What is the index size?
-
64K/(642) 216/(261)29
9
Memory Hierarchy Design
- Cache Performance
- Memory access time is an indirect measure of
performance and it is not a substitute for
execution time -
10
Memory Hierarchy Design
- Example 1 How much does cache help in
performance? -
11
Memory Hierarchy Design
- Example 2 Whats the relationship between AMAT
and CPU Time? -
12
Memory Hierarchy Design
- Improving Cache Performance
- The average memory access time can be improved by
reducing any of the three parameters above - R1 ? reducing miss rate
- R2 ? reducing miss penalty
- R3 ? reducing hit time
- Four categories of cache organizations that help
reduce these parameters - Organizations that help reduce miss rate
- larger block size, larger cache size, higher
associativity, way prediction and
pseudoassociativity, and compiler optimization - Organizations that help reduce miss penalty
- multilevel caches, critical word first, read
miss before write miss, merging write buffers,
and victim cache - Organizations that help reduce miss penalty or
miss rate via parallelism - non-blocking caches, hardware prefetching, and
compiler prefetching - Organizations that help reduce hit time
- small and simple caches, avoid address
translation, pipelined cache access, and trace
cache.
13
Memory Hierarchy Design
- Reducing Miss Rate
- There are three kinds of cache misses depending
on the causes - Compulsory the very first access to a block
cannot be a hit, since the block must be first
brought in from the main memory. Also call
cold-start misses - Capacity lack of space in cache to hold all
blocks needed for the execution. Capacity misses
will occur because of blocks being discarded and
later retrieved - Conflict due to mapping that confines blocks to
restricted area of cache (e.g., direct mapping,
set-associative), also called collision misses or
interference misses - While 3-C characterization gives insights to
causes, they are at times too simplistic (and
they are inter-dependent). For example, they
ignore replacement policies.
14
Memory Hierarchy Design
- Roles of
- 3-C
15
Memory Hierarchy Design
- Roles of 3-C
16
Memory Hierarchy Design
- First Miss Rate Reduction Technique Large Block
Size - Takes advantage of spatial locality ? reduces
compulsory miss - Increases miss penalty (it takes longer to fetch
a block) - Increases conflict misses, and/or increases
capacity misses - Must strike a delicate balance among MP, MR, and
AMAT, in finding an appropriate block size
17
Memory Hierarchy Design
- First Miss Rate Reduction Technique Larger Block
Size - Example Find the optimal block size in terms of
AMAT, given that miss penalty is 40 cycles
overhead plus 2 cycles/16 bytes and miss rates of
the table below. - Solution AMAT HT MR MP HT MR (40
block size 2 / 16) - High latency and bandwidth encourages large block
size - Low latency and bandwidth encourages small block
size
18
Memory Hierarchy Design
- Second Miss Rate Reduction Technique Larger
Caches - An obvious way to reduce capacity misses.
- Drawback high overhead in terms of hit time and
higher cost. - Popular in off-chip cache (2nd and 3rd level
cache). - Third Miss Rate Reduction Technique Higher
Associativity - Miss rate
- Rule of Thumb
- 8-way associativity is almost equal to full
associativity - Miss rate of (1-way of N-sized cache) is almost
equal to Miss rate of (2-way of 0.5N-sized cache) - The higher the associativity, the longer the hit
time (why?) - Higher miss rate rewards higher associativity.
19
Memory Hierarchy Design
- Fourth Miss Rate Reduction Technique Way
Prediction and Pseudoassociative Caches - Way prediction helps select one block among those
in a set, thus requiring only one tag comparison
(if hit). - Preserves advantages of direct-mapping (why?)
- In case of a miss, other block(s) are checked.
- Pseudoassociative (also called column
associative) caches - Operate exactly as direct-mapping caches when
hit, thus again preserving advantages of the
direct-mapping - In case of a miss, another block is checked (as
if in set-associative caches), by simply
inverting the most significant bit of the index
field to find the other block in the pseudoset. - real hit time lt pseudo-hit time
- too many pseudo hits would defeat the purpose
20
Memory Hierarchy Design
- Fifth Miss Rate Reduction Technique Compiler
Optimizations
21
Memory Hierarchy Design
- Fifth Miss Rate Reduction Technique Compiler
Optimizations
22
Memory Hierarchy Design
- Fifth Miss Rate Reduction Technique Compiler
Optimizations
23
Memory Hierarchy Design
- Fifth Miss Rate Reduction Technique Compiler
Optimizations - Blocking improve temporal and spatial locality
- multiple arrays are accessed in both ways (i.e.,
row-major and column-major), namely, orthogonal
accesses that can not be helped by earlier
methods - concentrate on submatrices, or blocks
- All NN elements of Y and Z are accessed N times
and each element of X is accessed once. Thus,
there are N3 operations and 2N3 N2 reads!
Capacity misses are a function of N and cache
size in this case.
24
Memory Hierarchy Design
- Fifth Miss Rate Reduction Technique Compiler
Optimizations - To ensure that elements being accessed can fit in
the cache, the original code is changed to
compute a submatrix of size BB, where B is
called the blocking factor. - To total number of memory words accessed is
2N3//B N2 - Blocking exploits a combination of spatial (Y)
and temporal (Z) locality.
25
Memory Hierarchy Design
- First Miss Penalty Reduction Technique
Multilevel Caches - To keep up with the widening gap between CPU and
main memory, try to - make cache faster, and
- make cache larger
- by adding another, larger but slower
cache between cache and the main memory.
26
Memory Hierarchy Design
- First Miss Penalty Reduction Technique
Multilevel Caches - Local miss rate vs. global miss rate
- Local miss rate is defined as
- Global miss rate is defined as
27
Memory Hierarchy Design
- Second Miss Penalty Reduction Technique Critical
Word First and Early Restart - CPU needs just one word of the block at a time
- critical word first fetch the required word
first, and - early start as soon as the required word
arrives, send it to CPU. - Third Miss Penalty Reduction Technique Giving
Priority to Read Misses over Write Misses - Serves reads before writes have been completed
- while write buffers improve write-through
performance, they complicate memory accesses by
potentially delaying updates to memory - instead of waiting for the write buffer to become
empty before processing a read miss, the write
buffer is checked for content that might satisfy
the missing read. - in a write-back scheme, the dirty copy upon
replacing is first written to the write buffer
instead of the memory, thus improving
performance.
28
Memory Hierarchy Design
- Fourth Miss Penalty Reduction Technique Merging
Write Buffer - Improves efficiency of write buffers that are
used by both write-through and write back caches - Multiple single-word writes are combined into a
single write buffer entry which is otherwise used
for multi-word write. - Reduces stalls due to write buffer being full
29
Memory Hierarchy Design
- Fifth Miss Penalty Reduction Technique Victim
Cache - victim caches attempt to avoid miss penalty on a
miss by - Adding a small fully-associative cache that is
used to contain discarded blocks (victims) - It is proven to be effective, especially for
small 1-way cache. e.g., a 4-entry victim cache
removes 20 !
30
Memory Hierarchy Design
- Reducing Cache Miss Penalty or Miss Rate via
Parallelism - Nonblocking Caches (Lock-free caches)
- Hardware Prefetching of Instructions and Data
31
Memory Hierarchy Design
- Reducing Cache Miss Penalty or Miss Rate via
Parallelism - Compiler-Controlled Prefetching compiler inserts
prefetch instructions
32
Memory Hierarchy Design
- Reducing Cache Miss Penalty or Miss Rate via
Parallelism - Compiler-Controlled Prefetching An Example
- for(i0 ilt3 ii1)
- for(j0 jlt100 jj1)
- aij bj0 bj10
- 16-byte blocks, 8KB cache, 1-way write back,
8-byte elements What kind of locality, if any,
exists for a and b? - 3 rows and 100 columns spatial locality
even-indexed elements miss and odd-indexed
elements hit, leading to 3100/2 150 misses - 101 rows and 3 columns no spatial locality, but
there is temporal locality same element is used
in ith and (i 1)st iterations and the same
element is access in each i iteration. 100 misses
for i 0 and 1 miss for j 0 for a total of 101
misses - Assuming large penalty (50 cycles and at least 7
iterations must be prefetched). Splitting the
loop into two, we have
33
Memory Hierarchy Design
- Reducing Cache Miss Penalty or Miss Rate via
Parallelism - Compiler-Controlled Prefetching An Example
(continued) - for(j0 jlt100 jj1)
- prefetch(bj70
- prefetch(a0j7
- a0j bj0 bj10
- for(i1 ilt3 ii1)
- for(j0 jlt100 jj1)
- prefetch(aij7
- aij bj0 bj10
- Assuming that each iteration of the pre-split
loop consumes 7 cycles and no conflict and
capacity misses, then it consumes a total of
7300 25150 14650 cycles (total iteration
cycles plus total cache miss cycles) whereas the
split loop consumes a total of (117)100(47)5
0(17)200(44)50 3450
34
Memory Hierarchy Design
- Reducing Cache Miss Penalty or Miss Rate via
Parallelism - Compiler-Controlled Prefetching An Example
(continued) - the first loop consumes 9 cycles per iteration
(due to the two prefetch instruction) - the second loop consumes 8 cycles per iteration
(due to the single prefetch instruction), - during the first 7 iterations of the first loop
array a incurs 4 cache misses, - array b incurs 7 cache misses,
- during the first 7 iterations of the second loop
for i 1 and i 2 array a incurs 4 cache misses
each - array b does not incur any cache miss in the
second split!.
35
Memory Hierarchy Design
- First Hit Time Reduction Technique Small and
simple caches - smaller is faster
- small index, less address translation time
- small cache can fit on the same chip
- low associativity in addition to a
simpler/shorter tag check, 1-way cache allows
overlapping tag check with transmission of data
which is not possible with any higher
associativity! - Second Hit Time Reduction Technique Avoid
address translation during indexing - Make the common case fast
- use virtual address for cache because most memory
accesses (more than 90) take place in cache,
resulting in virtual cache
36
Memory Hierarchy Design
- Second Hit Time Reduction Technique Avoid
address translation during indexing - Make the common case fast
- there are at least three important performance
aspects that directly relate to
virtual-to-physical translation - improperly organized or insufficiently sized TLBs
may create excess not-in-TLB faults, adding time
to program execution time - for a physical cache, the TLB access time must
occur before the cache access, extending the
cache access time - two-line address (e.g., an I-line and a D-line
address) may be independent of each other in
virtual address space yet collide in the real
address space, when they draw pages whose lower
page address bits (and upper cache address bits)
are identical - problems with virtual cache
- Page-level protection must be enforced no matter
what during address translation (solution copy
protection info from TLB on a miss and hold it in
a field for future virtual indexing/tagging) - when a process is switched in/out, the entire
cache has to be flushed out cause physical
address will be different each time, i.e., the
problem of context switching (solution process
identifier tag -- PID)
37
Memory Hierarchy Design
- Second Hit Time Reduction Technique Avoid
address translation during indexing - problems with virtual cache
- different virtual addresses may refer to the same
physical address, i.e., the problem of
synonyms/aliases - HW solution guarantee every cache block a unique
phy. Address - SW solution force aliases to share some address
bits (e.g., page-coloring) - Virtually indexed and physically tagged
- Third Hit Time Reduction Technique Pipelined
cache writes - the solution is to reduce CCT and increase of
stages increases instr. throughput - Fourth Hit Time Reduction Technique Trace caches
- Finds a dynamic sequence of instructions
including taken branches to load into a cache
block - Put traces of the executed instructions into
cache blocks as determined by the CPU - Branch prediction is folded in to the cache and
must be validated along with the addresses to
have a valid fetch. - Disadvantage store the same instructions
multiple times
38
Memory Hierarchy Design
- Main Memory and Organizations for Improving
Performance
39
Memory Hierarchy Design
- Main Memory and Organizations for Improving
Performance - Wider main memory bus
- Cache miss penalty decreases proportionally
- Cost
- wider bus (x n) and multiplexer (x n),
- expandability (x n), and
- error correction is more expensive
- Simple interleaved memory
- Potential parallelism with multiple DRAMs
- Sending address and accessing multiple bands in
parallel but transmitting data sequentially
(4244x444 cycles ? 16/44 0.4 byte/cycle) - Independent memory banks
40
Memory Hierarchy Design
- Main Memory and Organizations for Improving
Performance
41
Memory Hierarchy Design
- Main Memory and Organizations for Improving
Performance
42
Memory Hierarchy Design
- Virtual Memory
43
Memory Hierarchy Design
- Virtual Memory
44
Memory Hierarchy Design
- Virtual Memory
45
Memory Hierarchy Design
- Virtual Memory
- Fast address translation an example Alpha
21264 data TLB
- ASN is used as PID for virtual caches
- TLB is not flushed on a context switch but only
when ASNs are recycled - Fully associative placement
46
Memory Hierarchy Design
- Virtual Memory
- What is the optimal page size? It depends
- page table size 1/page size
- large page size makes virtual cache possible
(avoiding the aliases problem), thus reducing
cache hit time - transfer of larger pages (over the network) is
more efficient efficiency of transfer - small TLB favors larger pages
- main drawback for large page size
- internal fragmentation waste of storage
- process startup time large context switching
overhead
47
Memory Hierarchy Design
- Summarizing Virtual Memory Caches
- A hypothetical memory hierarchy going from
virtual address to L2 cache access
48
Memory Hierarchy Design
- Protection and Examples of Virtual Memory
- The invention of multiprogramming led to the need
to share computer resources such as CPU, memory,
I/O, etc. by multiple programs whose
instantiations are called processes - Time-sharing of computer resources by multiple
processes requires that processes take turns
using such resources and designers of operating
systems and computer must ensure that the
switching among different processes, also called
context switching is done correctly - The computer designer must ensure that the CPU
portion of the process state can be saved and
restored - The operating systems designer must guarantee
that processes do not interfere with each others
computations - Protecting processes
- Base and Bound each process falls in a
pre-defined portion of the address space, that
is, an address is valid if Base ? Address ?
Bound, where OS keeps and defines the values of
Base and Bound in two registers.
49
Memory Hierarchy Design
- Protection and Examples of Virtual Memory
- The computer designers responsibilities in
helping the OS designer protect processes from
each other - Providing two modes to distinguish a user process
from a kernel process (or equivalently,
supervisor or executive process) - Providing a portion of the CPU state, including
the base/bound registers, the user/kernel mode
bit(s), and the exception enable/disable bit,
that a user can use but cannot write and - Providing mechanisms by which the CPU can switch
between the user mode to the supervisor mode. - While base-and-bound constitutes the minimum
protection system, virtual memory offers a more
fine-grained alternative to this simple model - Address translation provides an opportunity to
check any possible violations the read/write
and user/kernel signals from CPU vs. the
permission flags marked on individual pages by
virtual memory (or OS) to detect stray memory
accesses - Depending on the designers apprehension,
protection can be either relaxed or escalated. In
escalated protection, multiple levels of access
permissions can be used, much like the military
classification system.
50
Memory Hierarchy Design
- Protection and Examples of Virtual Memory
- A Paged Virtual Memory Example The Alpha Memory
Management and the 21264 TLB (one for Instruction
and one for Data) - A combination of segmentation and paging, with
48-bit virtual addresses while the 64-bit address
space being divided into three segments seg0
(bits 63-47 0..00), kseg (bits 63-46 010),
and seg1 (bits 63-46 111) - Advantages segmentation divides address space
and conserves page table space, while paging
provides virtual memory, relocation, and
protection - Even with segmentation, the size of the page
tables for the 64-bit address space is alarming.
A three-level hierarchical page table is used in
Alpha, with each PT contained in one page
51
Memory Hierarchy Design
- Protection and Examples of Virtual Memory
- A Paged Virtual Memory Example The Alpha Memory
Management and the 21264 TLB - PTE is 64 bits long, with the first 32 bits
contain the physical page number and the other
half includes the following five protection
fields - Valid whether the page number is valid for
address translation - User read enable allows user programs to read
data within this page - Kernel read enable -- allows kernel programs to
read data within this page - User write enable allows user programs to write
data within this page - Kernel write enable -- allows kernel programs to
write data within this page - Current design of Alpha has 8-KB pages, thus
allowing 1024 PTEs in each PT. The three page
level fields and page offset account for
1010101343 bits of the 64-bit virtual
address. The 21 bits to the left of level-1 field
are all 0s for seg0 and all 1s for seg1. - The maximum virtual address and physical address
is tied to the page size and Alpha has provisions
for future growth 16KB, 32KB and 64KB page sizes
for the future. - The following table shows memory hierarchy
parameters of the Alpha 21264 TLB
Parameter Description
Block size 1 PTE (8 bytes)
Hit time 1 clock cycle
Miss penalty (average) 20 clock cycle
TLB size 128 PTEs per TLB, each of which can map 1,8,64, or 512 pages
Block selection Round-robin
Write strategy (not applicable)
Block placement Fully associative
52
Memory Hierarchy Design
- Protection and Examples of Virtual Memory
- A Segmented Virtual Memory Example Protection
in the Intel Pentium - Pentium has four protection levels, with the
innermost level (0) corresponding to Alphas
kernel mode and the outermost level (3)
corresponding to Alphas user mode. Separate
stacks are used for each level to avoid security
breaches between levels. - User can call an OS routine and pass parameters
to it while retaining full protection - Allows the OS to maintain the protection level of
the called routine for the parameters that are
passed to it - The potential loophole in protection is prevented
by not allowing the user process to ask the OS to
access something indirectly that it would not
have been able to access itself (such security
loopholes are called Trojan Horse). - Bounds checking and memory mapping in Pentium by
the use of a descriptor table (DT, which plays
the role of PTs in the Alpha). The equivalent of
PTE in DT is a segment descriptor containing the
following fields - Present bit equivalent to the PTE valid bit,
used to indicate this is a valid translation - Base field equivalent to a page frame address,
containing the physical address of the first byte
of the segment - Access bit like the reference bit or use bit in
some architectures that is helpful for
replacement algorithms - Attributes field specifies the valid operations
and protection levels for the operations that use
this segment - Limit field not found in paged systems,
establishes the upper bound of valid offsets for
this segment.
53
Memory Hierarchy Design
- Crosscutting Issues The Design of Memory
Hierarchies - Superscalar CPU and Number of Ports to the Cache
- Cache must provide sufficient peak bandwidth to
benefit from multiple issues. Some processors
increase complexity of instruction fetch by
allowing instructions to be issued to be found on
any boundary instead of, say, multiples of 4
words. - Speculative Execution and the Memory System
- Speculative and conditional instructions generate
exceptions (by generating invalid addresses) that
would otherwise not occur, which in turn can
overwhelm the benefits of speculation with the
exception handling overhead. Such CPUs must be
matched with non-blocking caches and only
speculate on L1 misses (due to the unbearable
penalty of L2). - Combining Instruction Cache with Instruction
Fetch and Decode Mechanisms - Increasing demand for ILP and clock rate has led
to the merging of the first part of instruction
execution with instruction cache, by
incorporating trace cache (which combines branch
prediction with instruction fetch) and storing
the internal RISC operations in the trace cache
(e.g., Pentium 4s NetBurst microarchitecture). A
cache hit in the merged cache saves portion of
the instruction execution cycles. - Embedded Computer Caches and Real-Time
Performance - In real-time applications, variation of
performance matters much more than average
performance. Thus, caches that offer average
performance enhancement have to be used
carefully. Instruction caches are often used due
to the highly predictability of instructions
whereas data caches are locked down, forcing
them to act as small scratchpad memory under
program control. - Embedded Computer Caches and Power
- It is much more power efficient to access on-chip
memory than to access off-chip one (which needs
to drive the pins, buses and activate external
memory chips, etc). Other techniques, such as way
prediction, can be used to save power (by only
powering half of the two-way set-associative
cache). - I/O and Consistency of Cached Data
- Cache coherence problem must be addressed when
I/O devices also share the same cached data.
54
Memory Hierarchy Design
- An Example of the Cache Coherence Problem
55
Memory Hierarchy Design
- Putting It All Together Alpha 21264 Memory
Hierarchy
- Instruction cache is virtually indexed and
virtual tagged Data cache is virtually indexed
but physically tagged - Operations
- Chip loads instr serially from an external PROM
and loads configuration info for L2 cache - Execute preloaded code in PAL mode to initialize
e.g., update TLB - Once OS ready, it sets PC to appropriate addr in
seg0 - 9 index 1 way-predict 2 4-instr 12 addr
bits are sent to I- 48 9 6 33 bits for v.
tag - Way-prediction and Line-prediction (11-bit for
next 16-byte group on a miss and updated by br
prediction) are used to reduce I- latency - The next way and line prediction is loaded to
read the next block (step 3) on an intr cache
hit. - An instr miss leads to a check of I-TLB
prefetcher (4 7), or access L2 (if instr.
Addr. Not found) (8) - L2 is direct mapped, 1-16MB
56
Memory Hierarchy Design
- Putting It All Together Alpha 21264 Memory
Hierarchy - The instruction prefetcher does not rely on TLB
for address translation, it simply increments the
physical address of the miss by 64 bytes,
checking to make sure that the new address is
within the same page. Prefetching is suppressed
if new address is out of the page (step 14). - If the instruction is not found in L2, the
physical address command is sent to the ES40
system chip set via four consecutive transfer
cycles on a narrow, 15-bit outbound address bus
(step 15). Address and command take 8 CPU cycles.
CPU is connected to memory via a crossbar to one
of two 256-bit memory buses (16) - Total penalty of the instruction miss is about
130 CPU cycles for critical instructions, while
the rest of the block is filled at a rate of 8
bytes per 2 CPU cycles (step 17). - A victim file is associated with L2, a
write-back cache, to store a replaced block
(victim block) (step 18) The address of the
victim is sent out the system address bus
following the address of the new request (step
19), where the system chip set later extracts the
victim data and writes to the memory. - D- is a 64-KB two-way set-associative,
write-back cache, which is virtually indexed but
physically tagged. While the 9-bit index 3-bit
word selection is sent to index the required data
(step 24), virtual page is being translated at
D-TLB (step 23), which is fully associative and
has 128 PTEs of which each represents page size
from 8KB to 4MB (step 25).
57
Memory Hierarchy Design
- Putting It All Together Alpha 21264 Memory
Hierarchy - A TLB miss will trap to PAL (privileged
architecture library) code to load the valid PTE
for this address. In the worst case, a page-fault
happens, in which case OS will bring the page
from disk while context is switched. - The index field of the address is sent to both
sets of data cache (step 26). Assuming a TLB hit,
the two tags and valid bits are compared to the
physical page (steps 27-28), with a match
sending the desired 8 bytes to the CPU (step 29) - A miss at D- goes to L2 , which proceeds
similary to an instruction miss (step 30), except
that it must check the victim buffer to make sure
the block is not there (step 31) - A write-back victim can be produced on a data
cache miss. The victim data are extracted from
the data cache simultaneously with the fill of
the data cache with the L2 data and sent to the
victim buffer (step 32) - In case of a L2 miss, the fill data from the
system is written directly into the (L1) data
cache (step 33). The L2 is written only with L1
victims (step 34).
58
Memory Hierarchy Design
- Another View The Emotion Engine of the Sony
Playstation 2 - 3 Cs captured by cache for SPEC2000 (left) and
multimedia applications (right)
59
Memory Hierarchy Design
- Another View The Emotion Engine of the Sony
Playstation 2
Recommended
