
A Framework for Highly-Available Real-Time Internet Services - PowerPoint PPT Presentation
Title:
A Framework for Highly-Available Real-Time Internet Services
Description:
UDP heart-beat every 300ms. Measure gaps between receipt of successive heart-beats ... 10s of minutes, Labovitz & Ahuja, ... Claim: upper bound is: one per AS ... – PowerPoint PPT presentation
Number of Views:20
Avg rating:3.0/5.0
Title: A Framework for Highly-Available Real-Time Internet Services
1
A Framework for Highly-Available Real-Time
Internet Services
- Bhaskaran Raman,
- EECS, U.C.Berkeley
2
Problem Statement
- Real-time services with long-lived sessions
- Need to provide continued service in the face of
failures
3
Problem Statement
Video-on-demand server
Client
- Goals
- Quick recovery
- Scalability
4
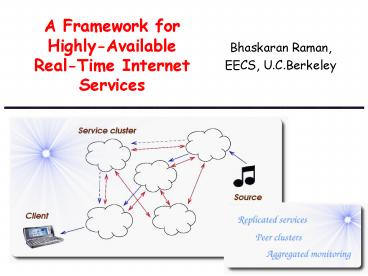
Our Approach
- Service infrastructure
- Computer clusters deployed at several points on
the Internet - For service replication path monitoring
- (path path of the data stream in a client
session)
5
Summary of Related Work
- Fail-over within a single cluster
- Active Services (e.g., video transcoding)
- TACC (web-proxy)
- Only service failure is handled
- Web mirror selection
- E.g., SPAND
- Does not handle failure during a session
- Fail-over for network paths
- Internet route recovery
- Not quick enough
- ATM, Telephone networks, MPLS
- No mechanism for wide-area Internet
No architecture to address network path failure
during a real-time session
6
Research Challenges
- Wide-area monitoring
- Feasibility how quickly and reliably can
failures be detected? - Efficiency per-session monitoring would impose
significant overhead - Architecture
- Who monitors who?
- How are services replicated?
- What is the mechanism for fail-over?
7
Is Wide-Area Monitoring Feasible?
Monitoring for liveness of path using keep-alive
heartbeat
Time
Failure detected by timeout
Time
Timeout period
False-positive failure detected incorrectly
Time
Timeout period
Theres a trade-off between time-to-detection and
rate of false-positives
8
Is Wide-Area Monitoring Feasible?
- False-positives due to
- Simultaneous losses
- Sudden increase in RTT
- Related studies
- Internet RTT study, Acharya Saltz, UMD 1996
- RTT spikes are isolated
- TCP RTO study, Allman Paxson, SIGCOMM 1999
- Significant RTT increase is quite transient
- Our experiments
- Ping data from ping servers
- UDP heartbeats between Internet hosts
9
Ping measurements
Berkeley
- Ping servers
- 12 geographically distributed servers chosen
- Approximation of a keep-alive stream
- Count number of loss runs with gt 4 simultaneous
losses - Could be an actual failure or just intermittant
losses - If we have 1 second HBs, and timeout after losing
4 HBs - This count gives the upper bound on the number of
false-positives
HTTP
1
3
Ping server
ICMP
2
Internet host
10
Ping measurements
Ping server Ping host Total time gt 4 misses
cgi.shellnet.co.uk hnets.uia.ac.be 151414 12
hnets.uia.ac.be sites.inka.de 205558 29
cgi.shellnet.co.uk hnets.uia.ac.be 145314 0
www.hit.net d18183f47.rochester.rr.com 202732 10
d18183f47.rochester.rr.com www.his.com 173031 0
www.hit.net www.his.com 20285 2
www.csu.net zeus.lyceum.com 20115 17
zeus.lyceum.com www.atmos.albany.edu 20117 62
www.csu.net www.atmos.albany.edu 20118 7
www.interworld.net www.interlog.com 141944 6
www.interlog.com inoc.iserv.net 20327 24
www.interworld.net inoc.iserv.net 143956 0
11
UDP-based keep-alive stream
- Geographically distributed hosts
- Berkeley, Stanford, UIUC, TU-Berlin, UNSW
- UDP heart-beat every 300ms
- Measure gaps between receipt of successive
heart-beats - False positive
- No heartbeat received for gt 2 seconds, but
received before 30 seconds - Failure
- No HB for gt 30 seconds
12
UDP-based keep-alive stream
HB destination HB source Total time Num. False positives
Berkeley UNSW 1304845 135
UNSW Berkeley 1305145 9
Berkeley TU-Berlin 1304946 27
TU-Berlin Berkeley 1305011 174
TU-Berlin UNSW 1304811 218
UNSW TU-Berlin 1304638 24
Berkeley Stanford 1242155 258
Stanford Berkeley 1242119 2
Stanford UIUC 895317 4
UIUC Stanford 763910 74
Berkeley UIUC 895411 6
UIUC Berkeley 763940 3
13
What does this mean?
- If we have a failure detection scheme
- Timeout of 2 sec
- False positives can be as low as once a day
- For many pairs of Internet hosts
- In comparison, BGP route recovery
- gt 30 seconds
- Can take upto 10s of minutes, Labovitz Ahuja,
SIGCOMM 2000 - Worse with multi-homing (an increasing trend)
14
Architectural Requirements
- Efficiency
- Monitoring per-session ? too much overhead
- End-to-end ? more latency ? monitoring less
effective - Need aggregation
- Client-side aggregation using a SPAND-like
server - Server-side aggregation clusters
- But not all clients have the same server
vice-versa - Service infrastructure to address this
- Several service clusters on the Internet
15
Architecture
Overlay topology Nodes service clusters Links
monitoring channels between clusters
Source ? Client Routed via monitored paths Could
go through an intermediate service Local recovery
using a backup path
16
Architecture
Monitoring within cluster for process/machine
failure
Monitoring across clusters for network path
failure
Peering of service clusters to server as
backups for one another or for monitoring the
path between them
17
Architecture Advantages
- 2-level monitoring ?
- Process/machine failures still handled within
cluster - Common failure cases do not require wide-area
mechanisms - Aggregation of monitoring across clusters ?
- Efficiency
- Model works for cascaded services as well
S1
Source
S2
Client
18
Architecture Potential Criticism
- Potential criticism
- Does not handle resource reservation
- Response
- Related issue, but could be orthogonal
- Aggregated/hierarchical reservation schemes
(e.g., the Clearing House) - Even if reservation is solved (or is not needed),
we still need to address failures
19
Architecture Issues(1) Routing
Internet
Source
Given the overlay topology, Need a routing
algorithm to go from source to destination via
service(s) Also need (a) WA-SDS, (b) Closest
service cluster to a given host
Client
20
Architecture Issues(2) Topology
How many service-clusters? (nodes) How many
monitored-paths? (links)
21
Ideas on Routing
Similarities with BGP
- BGP
- Border router
- Peering session
- Heartbeats
- IP route
- Destination based
- Service infrastructure
- Service cluster
- Peering session
- Heartbeats
- Route across clusters
- Based on destination and intermediate service(s)
22
Ideas on Routing
- How is routing in the overlay topology different
from BGP? - Overlay topology
- More freedom than physical topology
- Constraints on graph can be imposed more easily
- For example, can have local recovery
23
Ideas on Routing
Source
AP1
AP2
Client
AP3
BGP exchanges a lot of information Increases with
the number of APs O(100,000)
Service clusters need to exchange very little
information Problems of (a) Service discovery (b)
Knowing the nearest service cluster are
decoupled from routing
24
Ideas on Routing
- BGP routers do not have per-session state
- But, service clusters can maintain per-session
state - Can have local recovery pre-determined for each
session - Finally, we probably dont need to have as many
nodes as the number of BGP routers - can have more aggressive routing algorithm
It is feasible to have fail-over in the overlay
topology quicker than Internet route recovery
with BGP
25
Ideas on topology
- Decision criteria
- Additional latency for client session
- Sparse topology ? more latency
- Monitoring overhead
- Many monitored paths ? more overhead, but
additional flexibility ? might reduce end-to-end
latency
26
Ideas on topology
- Number of nodes
- Claim upper bound is one per AS
- This will ensure that there is a service cluster
close to every client - Topology will be close to Internet backbone
topology - Number of monitoring channels
- AS 7000 as of 1999
- Monitoring overhead 100 Bytes/sec
- Can have 1000 peering sessions per service
cluster easily - Dense overlay topology possible (to minimize
additional latency)
27
Implementation Performance
Service cluster
Exchange of session-information Monitoring
heartbeat
Peer cluster
Manager node
28
Implementation Performance
- PCM ?? GSM codec service
- Overhead of hot backup service 1 process
(idle) - Service reinstantiation time 100ms
- End-to-end recovery over wide-area three
components
Detection time O(2sec)
Communication with replica RTT O(100ms)
Replica activation 100ms
29
Implementation Performance
- Overhead of monitoring
- Keep-alive heartbeat
- One per 300ms in our implementation
- O(100Bytes/sec)
- Overhead of false-positive in failure detection
- Session transfer
- One message exchange across adjacent clusters
- Few hundred bytes
30
Summary
- Real-time applications with long-lived sessions
- No support exists for path-failure recovery
(unlike say, the PSTN) - Service infrastructure to provide this support
- Wide-area monitoring for path liveness
- O(2sec) failure detection with low rate of false
positives - Peering and replication model for quick fail-over
- Interesting issues
- Nature of overlay topology
- Algorithms for routing and fail-over
31
Questions
- What are the factors in deciding topology?
- Strategies for handling failure near
client/source - Currently deployed mechanisms for RIP/OSPF,
ATM/MPLS failure recovery - What is the time to recover?
- Applications video/audio streaming
- More?
- Games? Proxies for games on hand-held devices?
http//www.cs.berkeley.edu/bhaskar (Presentation
running under VMWare under Linux)
Recommended
CrystalGraphics Presentations





























