
Steps%20in%20Creating%20a%20Parallel%20Program - PowerPoint PPT Presentation
Title:
Steps%20in%20Creating%20a%20Parallel%20Program
Description:
E.g. which process computes which grid points or rows ... Orchestration in Grid Solver ... Simple example: nearest-neighbor grid computation ... – PowerPoint PPT presentation
Number of Views:49
Avg rating:3.0/5.0
Title: Steps%20in%20Creating%20a%20Parallel%20Program
1
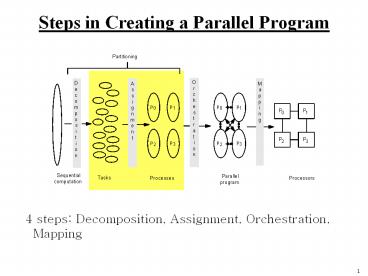
Steps in Creating a Parallel Program
- 4 steps Decomposition, Assignment,
Orchestration, Mapping
2
Assignment in the Grid Solver
- Static assignments (given decomposition into
rows) - block assignment of rows Row i is assigned to
process - cyclic assignment of rows process i is assigned
rows i, ip, and so on
- Dynamic assignment
- get a row index, work on the row, get a new row,
and so on - Static assignment into rows reduces concurrency
(from n to p) - block assign. reduces communication by keeping
adjacent rows together
3
Assignment More Generally
- Specifying mechanism to divide work up among
processes - E.g. which process computes which grid points or
rows - Together with decomposition, also called
partitioning - Goals Balance workload, reduce communication and
management cost - Structured approaches usually work well
- Code inspection (parallel loops) or understanding
of application - Well-known heuristics
- Static versus dynamic assignment
- We usually worry about partitioning (decomp.
assignment) first - Usually independent of architecture or prog model
- But cost and complexity of using primitives may
affect decisions - Lets dig into orchestration under three
programming models
4
Steps in Creating a Parallel Program
- 4 steps Decomposition, Assignment,
Orchestration, Mapping
5
Orchestration in Grid Solver
Logically shared Global diff
Border rows
- How to access (including communicate) logically
shared border rows from neighbors in each
iteration? - How to update, and ensure atomicity of updates
to, logically shared diff value in each iteration?
6
Data Parallel Solver
7
Shared Address Space Solver
Single Program Multiple Data (SPMD)
- Assignment controlled by values of variables used
as loop bounds
8
(No Transcript)
9
Notes on SAS Program
- SPMD not lockstep or even necessarily same
instructions - Assignment controlled by values of variables used
as loop bounds - unique pid per process, used to control
assignment - Done condition evaluated redundantly by all
- Code that does the update identical to sequential
program - each process has private mydiff variable
- Most interesting special operations are for
synchronization - accumulations into shared diff have to be
mutually exclusive - why the need for all the barriers?
10
Need for Mutual Exclusion
- Code each process executes
- load the value of diff into register r1
- add the register r2 to register r1
- store the value of register r1 into diff
- A possible interleaving
- P1 P2
- r1 ? diff P1 gets 0 in its r1
- r1 ? diff P2 also gets 0
- r1 ? r1r2 P1 sets its r1 to 1
- r1 ? r1r2 P2 sets its r1 to 1
- diff ? r1 P1 sets cell_cost to 1
- diff ? r1 P2 also sets cell_cost to 1
- Need the sets of operations to be atomic
(mutually exclusive)
11
Mutual Exclusion
- Provided by LOCK-UNLOCK around critical section
- Set of operations we want to execute atomically
- Implementation of LOCK/UNLOCK must guarantee
mutual excl. - Can lead to significant serialization if
contended - Especially since expect non-local accesses in
critical section - Another reason to use private mydiff for partial
accumulation
12
Global Event Synchronization
- BARRIER(nprocs) wait here till nprocs processes
get here - Built using lower level primitives
- Global sum example wait for all to accumulate
before using sum - Often used to separate phases of computation
- Process P_1 Process P_2 Process P_nprocs
- set up eqn system set up eqn system set up eqn
system - Barrier (name, nprocs) Barrier (name,
nprocs) Barrier (name, nprocs) - solve eqn system solve eqn system solve eqn
system - Barrier (name, nprocs) Barrier (name,
nprocs) Barrier (name, nprocs) - apply results apply results apply results
- Barrier (name, nprocs) Barrier (name,
nprocs) Barrier (name, nprocs) - Conservative form of preserving dependences, but
easy to use - WAIT_FOR_END (nprocs-1)
13
Pt-to-pt Event Synch (Not Used Here)
- One process notifies another of an event so it
can proceed - Common example producer-consumer (bounded
buffer) - Concurrent programming on uniprocessor
semaphores - Shared address space parallel programs
semaphores, or use ordinary variables as flags
- Busy-waiting or spinning
14
Group Event Synchronization
- Subset of processes involved
- Can use flags or barriers (involving only the
subset) - Concept of producers and consumers
- Major types
- Single-producer, multiple-consumer
- Multiple-producer, single-consumer
- Multiple-producer, single-consumer
15
Message Passing Grid Solver
- Cannot declare A to be shared array any more
- Need to compose it logically from per-process
private arrays - usually allocated in accordance with the
assignment of work - process assigned a set of rows allocates them
locally - Transfers of entire rows between traversals
- Structurally similar to SAS (e.g. SPMD), but
orchestration different - data structures and data access/naming
- communication
- synchronization
16
(No Transcript)
17
Notes on Message Passing Program
- Use of ghost rows
- Receive does not transfer data, send does
- unlike SAS which is usually receiver-initiated
(load fetches data) - Communication done at beginning of iteration, so
no asynchrony - Communication in whole rows, not element at a
time - Core similar, but indices/bounds in local rather
than global space - Synchronization through sends and receives
- Update of global diff and event synch for done
condition - Could implement locks and barriers with messages
- Can use REDUCE and BROADCAST library calls to
simplify code
18
Send and Receive Alternatives
Can extend functionality stride, scatter-gather,
groups Semantic flavors based on when control is
returned Affect when data structures or buffers
can be reused at either end
Send/Receive
Synchronous
Asynchronous
Blocking asynch.
Nonblocking asynch.
- Affect event synch (mutual excl. by fiat only
one process touches data) - Affect ease of programming and performance
- Synchronous messages provide built-in synch.
through match - Separate event synchronization needed with
asynch. messages - With synch. messages, our code is deadlocked.
Fix?
19
Orchestration Summary
- Shared address space
- Shared and private data explicitly separate
- Communication implicit in access patterns
- No correctness need for data distribution
- Synchronization via atomic operations on shared
data - Synchronization explicit and distinct from data
communication - Message passing
- Data distribution among local address spaces
needed - No explicit shared structures (implicit in comm.
patterns) - Communication is explicit
- Synchronization implicit in communication (at
least in synch. case) - mutual exclusion by fiat
20
Correctness in Grid Solver Program
- Decomposition and Assignment similar in SAS and
message-passing - Orchestration is different
- Data structures, data access/naming,
communication, synchronization
Requirements for performance are another story ...
21
Orchestration in General
- Naming data
- Structuring communication
- Synchronization
- Organizing data structures and scheduling tasks
temporally - Goals
- Reduce cost of communication and synch. as seen
by processors - Preserve locality of data reference (incl. data
structure organization) - Reduce serialization, and overhead of parallelism
management - Schedule tasks to satisfy dependences early
- Closest to architecture (and programming model
language) - Choices depend a lot on comm. abstraction,
efficiency of primitives - Architects should provide appropriate primitives
efficiently
22
Mapping
- After orchestration, we already have a parallel
program - Two aspects of mapping
- Which processes will run on same processor, if
necessary - Which process runs on which particular processor
- mapping to a network topology
- User specifies desires in some aspects, system
may ignore
23
Programming for Performance
24
Programming as Successive Refinement
- Rich space of techniques and issues
- Trade off and interact with one another
- Issues can be addressed/helped by software or
hardware - Algorithmic or programming techniques
- Architectural techniques
- Not all issues in programming for performance
dealt with up front - Partitioning often independent of architecture,
and done first - Then interactions with architecture
- Extra communication due to architectural
interactions - Cost of communication depends on how it is
structured - May inspire changes in partitioning
25
Partitioning for Performance
- Balancing the workload and reducing wait time at
synch points - Reducing inherent communication
- Reducing extra work
- Even these algorithmic issues trade off
- Minimize comm. gt run on 1 processor gt extreme
load imbalance - Maximize load balance gt random assignment of
tiny tasks gt no control over communication - Good partition may imply extra work to compute or
manage it - Goal is to compromise
- Fortunately, often not difficult in practice
26
Load Balance and Synch Wait Time
Sequential Work
- Limit on speedup Speedupproblem(p) lt
- Work includes data access and other costs
- Not just equal work, but must be busy at same
time - Four parts to load balance and reducing synch
wait time - 1. Identify enough concurrency
- 2. Decide how to manage it
- 3. Determine the granularity at which to exploit
it - 4. Reduce serialization and cost of
synchronization
Max Work on any Processor
27
Reducing Inherent Communication
- Communication is expensive!
- Metric communication to computation ratio
- Focus here on inherent communication
- Determined by assignment of tasks to processes
- Later see that actual communication can be
greater - Assign tasks that access same data to same
process - Solving communication and load balance NP-hard
in general case - But simple heuristic solutions work well in
practice - Applications have structure!
28
Domain Decomposition
- Works well for scientific, engineering, graphics,
... applications - Exploits local-biased nature of physical problems
- Information requirements often short-range
- Or long-range but fall off with distance
- Simple example nearest-neighbor grid
computation
- Perimeter to Area comm-to-comp ratio (area to
volume in 3-d) - Depends on n,p decreases with n, increases with
p
29
Domain Decomposition (contd)
Best domain decomposition depends on information
requirements Nearest neighbor example block
versus strip decomposition
- Comm to comp for block, for
strip - Application dependent strip may be better in
other cases - E.g. particle flow in tunnel
2p
n
30
Finding a Domain Decomposition
- Static, by inspection
- Must be predictable grid example above
- Static, but not by inspection
- Input-dependent, require analyzing input
structure - E.g sparse matrix computations
- Semi-static (periodic repartitioning)
- Characteristics change but slowly e.g. N-body
- Static or semi-static, with dynamic task stealing
- Initial domain decomposition but then highly
unpredictable e.g ray tracing
31
N-body Simulating Galaxy Evolution
- Simulate the interactions of many stars evolving
over time - Computing forces is expensive
- O(n2) brute force approach
- Hierarchical Methods take advantage of force law
G
m1m2
r2
- Many time-steps, plenty of concurrency across
stars within one
32
A Hierarchical Method Barnes-Hut
- Locality Goal
- Particles close together in space should be on
same processor - Difficulties Nonuniform, dynamically changing
33
Application Structure
- Main data structures array of bodies, of cells,
and of pointers to them - Each body/cell has several fields mass,
position, pointers to others - pointers are assigned to processes
34
Partitioning
- Decomposition bodies in most phases (sometimes
cells) - Challenges for assignment
- Nonuniform body distribution gt work and comm.
Nonuniform - Cannot assign by inspection
- Distribution changes dynamically across
time-steps - Cannot assign statically
- Information needs fall off with distance from
body - Partitions should be spatially contiguous for
locality - Different phases have different work
distributions across bodies - No single assignment ideal for all
- Focus on force calculation phase
- Communication needs naturally fine-grained and
irregular
35
Load Balancing
- Equal particles ? equal work.
- Solution Assign costs to particles based on the
work they do - Work unknown and changes with time-steps
- Insight System evolves slowly
- Solution Count work per particle, and use as
cost for next time-step. - Powerful technique for evolving physical systems
36
A Partitioning Approach ORB
- Orthogonal Recursive Bisection
- Recursively bisect space into subspaces with
equal work - Work is associated with bodies, as before
- Continue until one partition per processor
- High overhead for large no. of processors
37
Another Approach Costzones
- Insight Tree already contains an encoding of
spatial locality.
- Costzones is low-overhead and very easy to
program
38
Space Filling Curves
Peano-Hilbert Order
Morton Order
39
Rendering Scenes by Ray Tracing
- Shoot rays into scene through pixels in image
plane - Follow their paths
- they bounce around as they strike objects
- they generate new rays ray tree per input ray
- Result is color and opacity for that pixel
- Parallelism across rays
- All case studies have abundant concurrency
40
Partitioning
- Scene-oriented approach
- Partition scene cells, process rays while they
are in an assigned cell - Ray-oriented approach
- Partition primary rays (pixels), access scene
data as needed - Simpler used here
- Need dynamic assignment use contiguous blocks to
exploit spatial coherence among neighboring rays,
plus tiles for task stealing
A tile, the unit of decomposition and stealing
A block, the unit of assignment
Could use 2-D interleaved (scatter) assignment of
tiles instead
41
Other Techniques
- Scatter Decomposition, e.g. initial partition in
Raytrace
1
2
1
2
1
2
1
2
3
4
3
4
3
4
3
4
2
1
1
2
1
2
1
2
1
2
3
4
3
4
3
4
3
4
1
2
1
2
1
2
1
2
3
4
3
4
3
4
3
4
4
3
1
2
1
2
1
2
1
2
4
4
4
4
3
3
3
3
Domain decomposition
Scatter decomposition
- Preserve locality in task stealing
- Steal large tasks for locality, steal from same
queues, ...
42
Determining Task Granularity
- Task granularity amount of work associated with
a task - General rule
- Coarse-grained gt often less load balance
- Fine-grained gt more overhead often more comm.,
contention - Comm., contention actually affected by
assignment, not size - Overhead by size itself too, particularly with
task queues
43
Dynamic Tasking with Task Queues
- Centralized versus distributed queues
- Task stealing with distributed queues
- Can compromise comm and locality, and increase
synchronization - Whom to steal from, how many tasks to steal, ...
- Termination detection
- Maximum imbalance related to size of task
- Preserve locality in task stealing
- Steal large tasks for locality, steal from same
queues, ...
44
Reducing Extra Work
- Common sources of extra work
- Computing a good partition
- e.g. partitioning in Barnes-Hut or sparse matrix
- Using redundant computation to avoid
communication - Task, data and process management overhead
- applications, languages, runtime systems, OS
- Imposing structure on communication
- coalescing messages, allowing effective naming
- Architectural Implications
- Reduce need by making communication and
orchestration efficient
45
Its Not Just Partitioning
- Inherent communication in parallel algorithm is
not all - artifactual communication caused by program
implementation and architectural interactions can
even dominate - thus, amount of communication not dealt with
adequately - Cost of communication determined not only by
amount - also how communication is structured
- and cost of communication in system
- Both architecture-dependent, and addressed in
orchestration step
46
Spatial Locality Example
- Repeated sweeps over 2-d grid, each time adding
1 to elements - Natural 2-d versus higher-dimensional array
representation
47
Tradeoffs with Inherent Communication
- Partitioning grid solver blocks versus rows
- Blocks still have a spatial locality problem on
remote data - Rowwise can perform better despite worse inherent
c-to-c ratio
Good spacial locality on nonlocal accesses
at row-oriented boudary
Poor spacial locality on nonlocal accesses
at column-oriented boundary
- Result depends on n and p
48
Structuring Communication
- Given amount of comm (inherent or artifactual),
goal is to reduce cost - Cost of communication as seen by process
- C f ( o l tc - overlap)
- f frequency of messages
- o overhead per message (at both ends)
- l network delay per message
- nc total data sent
- m number of messages
- B bandwidth along path (determined by network,
NI, assist) - tc cost induced by contention per message
- overlap amount of latency hidden by overlap
with comp. or comm. - Portion in parentheses is cost of a message (as
seen by processor) - That portion, ignoring overlap, is latency of a
message - Goal reduce terms in latency and increase overlap
49
Reducing Overhead
- Can reduce no. of messages m or overhead per
message o - o is usually determined by hardware or system
software - Program should try to reduce m by coalescing
messages - More control when communication is explicit
- Coalescing data into larger messages
- Easy for regular, coarse-grained communication
- Can be difficult for irregular, naturally
fine-grained communication - may require changes to algorithm and extra work
- coalescing data and determining what and to whom
to send
50
Reducing Network Delay
- Network delay component fhth
- h number of hops traversed in network
- th linkswitch latency per hop
- Reducing f communicate less, or make messages
larger - Reducing h
- Map communication patterns to network topology
- e.g. nearest-neighbor on mesh and ring
all-to-all - How important is this?
- used to be major focus of parallel algorithms
- depends on no. of processors, how th, compares
with other components - less important on modern machines
- overheads, processor count, multiprogramming
51
Reducing Contention
- All resources have nonzero occupancy
- Memory, communication controller, network link,
etc. - Can only handle so many transactions per unit
time - Effects of contention
- Increased end-to-end cost for messages
- Reduced available bandwidth for other messages
- Causes imbalances across processors
- Particularly insidious performance problem
- Easy to ignore when programming
- Slow down messages that dont even need that
resource - by causing other dependent resources to also
congest - Effect can be devastating Dont flood a
resource!
52
Types of Contention
- Network contention and end-point contention
(hot-spots) - Location and Module Hot-spots
- Location e.g. accumulating into global variable,
barrier - solution tree-structured communication
- Module all-to-all personalized comm. in matrix
transpose - solution stagger access by different processors
to same node temporally - In general, reduce burstiness may conflict with
making messages larger
53
Overlapping Communication
- Cannot afford to stall for high latencies
- even on uniprocessors!
- Overlap with computation or communication to hide
latency - Requires extra concurrency (slackness), higher
bandwidth - Techniques
- Prefetching
- Block data transfer
- Proceeding past communication
- Multithreading
54
Summary of Tradeoffs
- Different goals often have conflicting demands
- Load Balance
- fine-grain tasks
- random or dynamic assignment
- Communication
- usually coarse grain tasks
- decompose to obtain locality not random/dynamic
- Extra Work
- coarse grain tasks
- simple assignment
- Communication Cost
- big transfers amortize overhead and latency
- small transfers reduce contention
55
Processors Perspective
1
0
0
1
0
0
S
y
n
c
h
D
a
t
a
-
r
e
m
o
t
e
B
u
s
y
-
u
s
e
f
u
l
B
u
s
y
-
o
v
e
r
h
e
a
d
D
a
t
a
-
l
o
c
a
l
7
5
7
5
)
)
s
s
(
(
e
e
m
m
i
i
5
0
5
0
T
T
2
5
2
5
P
P
P
P
0
1
2
3
(
a
)
S
e
q
u
e
n
t
i
a
l
(
b
)
P
a
r
a
l
l
e
l
w
i
t
h
f
o
u
r
p
r
o
c
e
s
s
o
r
s
56
Implications for Programming Models
- Coherent shared address space and explicit
message passing - Assume distributed memory in all cases
- Recall any model can be supported on any
architecture - Assume both are supported efficiently
- Assume communication in SAS is only through loads
and stores - Assume communication in SAS is at cache block
granularity
57
Issues to Consider
- Functional issues
- Naming
- Replication and coherence
- Synchronization
- Organizational issues
- Granularity at which communication is performed
- Performance issues
- Endpoint overhead of communication
- (latency and bandwidth depend on network so
considered similar) - Ease of performance modeling
- Cost Issues
- Hardware cost and design complexity
58
Naming
- SAS similar to uniprocessor system does it all
- MP each process can only directly name the data
in its address space - Need to specify from where to obtain or where to
transfer nonlocal data - Easy for regular applications (e.g. Ocean)
- Difficult for applications with irregular,
time-varying data needs - Barnes-Hut where the parts of the tree that I
need? (change with time) - Raytrace where are the parts of the scene that I
need (unpredictable) - Solution methods exist
- Barnes-Hut Extra phase determines needs and
transfers data before computation phase - Raytrace scene-oriented rather than ray-oriented
approach - both emulate application-specific shared address
space using hashing
59
Replication
- Who manages it (i.e. who makes local copies of
data)? - SAS system, MP program
- Where in local memory hierarchy is replication
first done? - SAS cache (or memory too), MP main memory
- At what granularity is data allocated in
replication store? - SAS cache block, MP program-determined
- How are replicated data kept coherent?
- SAS system, MP program
- How is replacement of replicated data managed?
- SAS dynamically at fine spatial and temporal
grain (every access) - MP at phase boundaries, or emulate cache in main
memory in software - Of course, SAS affords many more options too
(discussed later)
60
Communication Overhead and Granularity
- Overhead directly related to hardware support
provided - Lower in SAS (order of magnitude or more)
- Major tasks
- Address translation and protection
- SAS uses MMU
- MP requires software protection, usually
involving OS in some way - Buffer management
- fixed-size small messages in SAS easy to do in
hardware - flexible-sized message in MP usually need
software involvement - Type checking and matching
- MP does it in software lots of possible message
types due to flexibility - A lot of research in reducing these costs in MP,
but still much larger - Naming, replication and overhead favor SAS
- Many irregular MP applications now emulate
SAS/cache in software
61
Block Data Transfer
- Fine-grained communication not most efficient for
long messages - Latency and overhead as well as traffic (headers
for each cache line) - SAS can using block data transfer
- Explicit in system we assume, but can be
automated at page or object level in general
(more later) - Especially important to amortize overhead when it
is high - latency can be hidden by other techniques too
- Message passing
- Overheads are larger, so block transfer more
important - But very natural to use since message are
explicit and flexible - Inherent in model
62
Synchronization
- SAS Separate from communication (data transfer)
- Programmer must orchestrate separately
- Message passing
- Mutual exclusion by fiat
- Event synchronization already in send-receive
match in synchronous - need separate orchestratation (using probes or
flags) in asynchronous
63
Hardware Cost and Design Complexity
- Higher in SAS, and especially cache-coherent SAS
- But both are more complex issues
- Cost
- must be compared with cost of replication in
memory - depends on market factors, sales volume and other
nontechnical issues - Complexity
- must be compared with complexity of writing
high-performance programs - Reduced by increasing experience
64
Performance Model
- Three components
- Modeling cost of primitive system events of
different types - Modeling occurrence of these events in workload
- Integrating the two in a model to predict
performance - Second and third are most challenging
- Second is the case where cache-coherent SAS is
more difficult - replication and communication implicit, so events
of interest implicit - similar to problems introduced by caching in
uniprocessors - MP has good guideline messages are expensive,
send infrequently - Difficult for irregular applications in either
case (but more so in SAS) - Block transfer, synchronization, cost/complexity,
and performance modeling advantageus for MP
65
Summary for Programming Models
- Given tradeoffs, architect must address
- Hardware support for SAS (transparent naming)
worthwhile? - Hardware support for replication and coherence
worthwhile? - Should explicit communication support also be
provided in SAS? - Current trend
- Tightly-coupled multiprocessors support for
cache-coherent SAS in hw - Other major platform is clusters of workstations
or multiprocessors - currently dont support SAS in hardware, mostly
use message passing
66
Summary
- Crucial to understand characteristics of parallel
programs - Implications for a host or architectural issues
at all levels - Architectural convergence has led to
- Greater portability of programming models and
software - Many performance issues similar across
programming models too - Clearer articulation of performance issues
- Used to use PRAM model for algorithm design
- Now models that incorporate communication cost
(BSP, logP,.) - Emphasis in modeling shifted to end-points, where
cost is greatest - But need techniques to model application
behavior, not just machines - Performance issues trade off with one another
iterative refinement - Ready to understand using workloads to evaluate
systems issues
Recommended
CrystalGraphics Presentations





























