
Mining Sequential Patterns - PowerPoint PPT Presentation
Title:
Mining Sequential Patterns
Description:
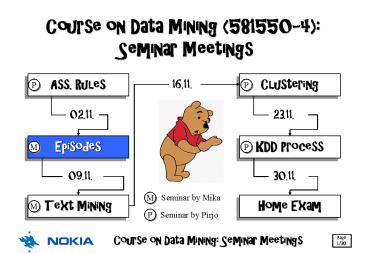
Ass. Rules. Episodes. Text Mining. 02.11. 09.11. Clustering. KDD Process. Home Exam. 23.11. ... Most of the sequences are large (85%) = next round is k 5 ... – PowerPoint PPT presentation
Number of Views:64
Avg rating:3.0/5.0
Title: Mining Sequential Patterns
1
Course on Data Mining (581550-4) Seminar
Meetings
Ass. Rules
Clustering
P
P
Episodes
KDD Process
P
M
Text Mining
Home Exam
M
2
Course on Data Mining (581550-4) Seminar
Meetings
Today 09.11.2001
- Rakesh Agrawal and Ramakrishnan Srikant Mining
Sequential Patterns. Int'l Conference on Data
Engineering, 1995. - F. Masseglia, P. Poncelet and M. Teisseire
Incremental Mining of Sequential Patterns in
Large Databases. 16èmes Journées Bases de Données
Avancées, 2000.
3
Mining Sequential Patterns
- Rakesh Agrawal and Ramakrishnan Srikant
- IBM Almaden Research Center, USA
- Published in ICDE'95 (Int'l Conf. on Data
Engineering) - Data Mining course Autumn 2001/University of
Helsinki - Summary by Mika Klemettinen
4
Mining Sequential Patterns
- Problem statement
- Database D with customer transactions
- Customer-id, transaction time, items purchased
- Quantities of items purchased are NOT concerned
- Definitions
- Itemset a non-empty set of items, ? i1 i2 i3 ?
- Sequence an ordered list of itemsets, ? s1 s2 s3
? - A sequence ? a1 a2 an ? is contained in ? b1 b2
bn ? if there exist i1 lt i2 lt ... lt in such
that a1 ? bi1, a2 ? bi2, an ? bin - E.g., ? (3)(4 5)(8) ? ? ? (7)(3 8)(9)(4 5 6)(8)gt,
since (3) ? (3 8), (4 5) ? (4 5 6) and (8) ? (8) - However, note that sequence ? (3)(5) ? ? ? (3 5)
? (and vice versa)
5
Mining Sequential Patterns
- Customer sequence a sequence of transactions
("shopping baskets") of a customer, ordered by
transaction times Ti ? itemset(T1)
itemset(T2) itemset(Tn) ? - A customer supports a sequence s if s is
contained in the customer sequence for this
customer - The support for a sequence is defined as the
fraction of total customers who support this
sequence - Task Given a database D of customer
transactions, the problem of mining sequential
patterns is to find the maximal sequences among
all sequences that have a certain user-specified
minimun support. Each such maximal sequence
represents a sequential pattern
6
Mining Sequential Patterns
- Customer Id Transaction time Items bought
- 1 June 25, 1993 30
- 1 June 30, 1993 90
- 2 June 10, 1993 10, 20
- 2 June 15, 1993 30
- 2 June 20, 1993 40, 60, 70
- ... ... ...
- Customer Id Customer sequence
- 1 ?(30)(90)?
- 2 ?(10 20)(30)(40 60 70)?
- 3 ?(30 50 70)?
- 4 ?(30)(40 70)(90)?
- 5 ?(90)?
Min. support 25 gt 2 customers lt(30)(90)gt (14)
and lt(30)(40 70)gt (24) are maximal
7
Mining Sequential Patterns
- Definitions
- Length of a sequence is the number of itemsets in
the sequence - A sequence of length k is called k-sequence
- A sequence concatenated from sequences x and y is
denoted by x.y - The support for an itemset i is defined as the
fraction of customers who bought the items in i
in a single transaction - An itemset with minimum support is called large
itemset or litemset - Each itemset in a large sequence must have
minimum support, i.e., any large sequence must be
a list of litemsets (Apriori trick!) - Three algorithms, all for sequential patterns
- AprioriSome
- AprioriAll
- DynamicSome
8
Mining Sequential Patterns
- Mining of sequential patterns
- 1. Sort Phase
- Sort according to customer Id and transaction
time - 2. Litemset Phase
- Find large itemsets in a Apriori fashion, but
like in MaxFreq, the support count is incremented
only once even if the customer buys the same set
of items in two different transactions - The large itemsets are mapped to a set of
contiguous integers (e.g. (30), (40), (70), (40
70) and (90) becomes 1, 2, 3, 4 and 5) checking
of equality is then fast (constant time)!
9
Mining Sequential Patterns
- 3. Transformation Phase
- There is a need to repeatedly check which large
itemsets are contained in customer sequences - To make this fast, each customer sequence is
transformed to a list of large itemsets - Then the large itemsets are mapped to integers
- CId Original seq. Transf. Mapping
- 1 ?(30)(90)? ?(30)(90)? ?15?
- 2 ?(10 20)(30)(40 60 70)? ?(30)(40),(70),(40
70)? ?12,3,4? - 3 ?(30 50 70)? ?(30),(70)? ?1,3?
- 4 ?(30)(40 70)(90)? ?(30)(40),(70),(40
70)(90)? ?12,3,45? - 5 ?(90)? ?(90)? ?5?
10
Mining Sequential Patterns
- 4. Sequence Phase
- The large itemsets are used to find the desired
sequences - AprioriAll
- Based on the normal Apriori algorithm
- Counts all the large sequences
- Prunes non-maximal in the "Maximal phase"
- Some
- Avoid counting sequences that are contained in
longer sequences by counting the longer ones
first, also avoid having to count many
subsequences because their supersequences are not
large
11
Mining Sequential Patterns
- Forward phase find all large sequences of
certain lengths - Backward phase find all remaining large
sequences - AprioriSome use only large sequences from
previous pass to generate candidates and validate
their supports (i.e., if they are frequent or
not) - DynamicSome generate candidates on-the-fly based
on large sequences found from the previous passes
and the customer sequences read from the database - 5. Maximal Phase
- Find the maximal sequences among the large
sequences - In practice, starting from the largest sequences,
delete all their subsequences
12
Mining Sequential Patterns
- AprioriAll
- Find all large sequences "normally"
- Prune the non-maximal ones away starting from ? 1
2 3 4 ? by deleting all its subsequences (? 1 2 3
?, ? 1 2 4 ?, ? 1 3 4 ?, ? 2 3 4 ?, ? 1 2 ?, ? 1
3 ?, , ? 4 ?), then take the remaining ? 1 3 5 ?
and prune all its subsequences, - The maximal large sequences are ? 1 2 3 4 ?, ? 1
3 5 ? and ? 4 5 ?
13
Mining Sequential Patterns
- AprioriSome
- Count only sequences of, e.g., length 1, 2, 4 and
6 in "forward phase" and count sequences of
length 3 and 5 in "backward phase" - Note in the forward phase, candidates for all
levels are counted - If in the large sequences of length Lk-1were
checked, then generate new candidates Ck based on
them - If in the large sequences of length Lk-1were NOT
checked, then generate new candidates Ck based on
candidates Ck-1 - In backward phase delete all sequences of the
length k in candidate collection if they are
contained in some longer large sequence Li (i gt k)
14
Mining Sequential Patterns
- Function "next" determines the next sequence
length which is counted this is based on the
assumption that if, e.g, almost all sequences of
length k are large (frequent), then many of the
sequences of length k1 are also large
(frequent). E.g., - Most of the sequences are large (85) gt next
round is k5 - ...
- Not many of the sequences are large (67) gt next
round is k1 (AprioriAll)
15
Mining Sequential Patterns
- DynamicSome
- In the initialization phase, count only sequences
upto and including step variable length - E.g., if step is 3, count sequences of length 1,
2 and 3 - In the forward phase, we generate sequences of
length 2 step, 3 step, 4 step, etc.
on-the-fly based on previous passes and customer
sequences in the database - E.g., while generating sequences of length 9 with
a step size 3 While passing the data, if
sequences s6 ? L6 and s3 ? L3 are both contained
in the customer sequence c in hand, and they do
not overlap in c, then ? sk . sj ? is a candidate
(kj)-sequence
16
Mining Sequential Patterns
- In the intermediate phase, generate the candidate
sequences for the skipped lengths - E.g., if we have counted L6 and L3 , and L9 turns
out to be empty we generate C7 and C8 , count C8
followed by C7 after deleting non-maximal
sequences, and repeat the process for C4 and C5 - The backward phase is identical to AprioriSome
- Then we go on and spare a few thoughts on
incremental mining of sequential patterns
17
Incremental Mining of Sequential Patterns in
Large Databases
- F. Masseglia, P. Poncelet and M. Teisseire
- Laboratoire PRiSM LIRMM UMR CNRS, France
- Published in BDA'00 (Bases de Données Avancées)
- Data Mining course Autumn 2001/University of
Helsinki - Summary by Mika Klemettinen
18
Incremental Mining of Sequential Patterns
- Problem setting
- Let us consider an original and an incremental
customer transaction database - For the original database, the frequent patterns
have been created - Incremental database may contain new customers
and new transactions for both old and new
customers - To compute the set of sequential patterns in the
updated database, we want to avoid counting
everything from the scratch - Some main things one has to consider
- Discover all sequential patterns NOT frequent in
the original database but become frequent with
the increment - Examine all transactions in the original database
which can be extended to become frequent - Old frequent sequences may become invalid when
adding a customer or customers
19
Incremental Mining of Sequential Patterns
- Definitions are basically the same as in "Mining
Sequential Patterns" paper - Again, the problem is to find all (maximal)
sequences whose support is greater than a
specified threshold (minimum support) - Additional definitions
- DB is the original database, minSupp is the
minimum support - db is the increment database
- U DB ? db is the updated database containing
all sequences from DB and db - LDB is the set of frequent sequences in DB
- Task is to find frequent sequences in U, noted
LU, with respect to the minSupp - An example database is presented on the next
slide
20
Incremental Mining of Sequential Patterns
21
Incremental Mining of Sequential Patterns
- First problem (Figure 1) Append new transactions
to customers already existing in the original
database - Suppose that we have minSupp threshold of 50
- In the original database, the frequent (maximal)
sequences LDB are - ? (10 20) (30) ?, ? (10 20) (40) ?
- New transactions are appended to customers C2 and
C3 - Sequences ? (60) (90) ? and ? (10 20) (50 70) ?
become frequent - Customers C3 and C4 contain the first one, thus
support is 50 - Customers C1, C2, and C3 contain ? (10 20) ?,
thus the increments for C2 and C3 make the second
one frequent, since customers C1 and C2 contain
it thus support is 50 - Sequences ? (10 20) (30)(50 60)(80) ? and ? (10
20) (40)(50 60)(80) ? become frequent, since ?
(50 60) (80) ? is frequent in db and was added to
the rows already containing frequent sequences ?
(10 20) (30) ? and ? (10 20) (40) ?
22
Incremental Mining of Sequential Patterns
- Second problem (Figure 2) Append new customers
and new transactions to the original database - Suppose again that we have minSupp threshold of
50 - When one new customer is added to the database, a
frequent sequence must be observed for 3
customers (previously 2) - In the original database, the frequent (maximal)
sequences LDB used to be ? (10 20) (30) ?, ? (10
20) (40) ?, but is now just ? (10 20) ? - Sequences ? (10 20) (30) ? and ? (10 20) (40) ?
occur only for customers C2 and C3 - Sequence ? (10 20) ? occurs for C1, C2, and C3
- By introducing increment database db, the LU
becomes ? (10 20) (50) ?, ? (10) (70) ?, ? (10)
(80) ?, ? (40) (80) ?, ? (60) ? - E.g., sequence ? (10 20) (50) ? is in the
original database only for C1, and is not
frequent as the item 50 becomes frequent with
the increment database, the sequence matches also
C2 and C3
23
Incremental Mining of Sequential Patterns
- Algorithm (ISE) The incremental mining is
decomposed into two subproblems (k length of
the longest frequent sequences in DB) - Find all new frequent sequences of size j ?
(k1). During this phase, three kinds of frequent
sequences are considered - Sequences in DB can become frequent since they
have sufficient support with the increment - There can be new frequent sequences appearing in
increment db but not in original DB - Sequences in DB can become frequent when adding
items of db - Find all new frequent sequences of size j gt (k1)
- This is straightforward Apriori-like algorithm
applying, since we have all frequent
(k1)-sequences discovered in the previous phase
24
Incremental Mining of Sequential Patterns
- First iteration (1)
- Make a pass on db, count support for individual
items of db - Provide 1-candExt, sequences occurring in db
- Determine which items of db are frequent in U gt
Ld1b - Prune out frequent sequences that used to be
frequent in LDB, but which are no more frequent
in U
25
Incremental Mining of Sequential Patterns
- First iteration (2)
- Create candidate sequences of length 2 by joining
Ld1b with Ld1b gt 2-candExt - Generate from LDB the set of frequent
sub-sequences - Scan U to find out frequent 2-sequences from
2-candExt and frequent sub-sequences occurring
before items of Ld1b
26
Incremental Mining of Sequential Patterns
- First iteration (3)
- freqSeed lt frequent sub-sequences occurring
before items of Ld1b and appended with the item - 2-freqExt lt frequent 2-sequences from 2-candExt
27
Incremental Mining of Sequential Patterns
- j th iteration with j ? (k1)
- While (j-freqExt ! ? AND j ? (k1) do
- candInc lt Generate candidates from freqSeed
and j-freqExt - j
- j-candExt lt Generate candidate j-sequences
from (j-1)freqExt - Scan db for j-candExt
- if (j-candExt ! ? AND candInc ! ?) then
- Scan U for j-candExt and candInc
- endif
- j-freqExt lt frequent j-sequences
- freqInc lt freqInc candidates from candInc
verifying the support on U - enddo
- LU lt LDB ? max. freq. sequences in freqSeed
? freqInc ? freqExt
28
Incremental Mining of Sequential Patterns
- j th iteration with j gt (k1)
- Apply Apriori-style algortihm until all frequent
sequences are discovered - LU lt LU ? max. freq. sequences obtained from
the previous step - On the next slide, processes in the first and j
th iteration with j gt (k1) are summarized - Optimization in "candInc lt Generate candidates
from freqSeed and j-freqExt " - Consider two sequences (s ? freqSeed, s' ?
freqExt) such that an item i ? Ld1b is the last
item of s and the first item of s' - Do not append s' ? freqExt to s ? freqSeed if
there exist an item j ? Ld1b such that j is in
s' and j is not preceded by s
29
Incremental Mining of Sequential Patterns
30
Unofficial Evaluation (Personal Views)
- Mining Sequential Patterns
- Paper comes from one of the top research groups
in data mining area (IBM Almaden Data Mining
group led by Rakesh Agrawal) - Quite well-written paper Good language, clear
examples and presentation gt rather "easy to
read" - Simple ideas, not very "break-through" ideas (at
least this is the interpretation now) quite good
international conference - One has to remember this is written already in
1995 - Incremental Mining of Sequential Patterns in
Large Databases - Paper comes from not so well-known French
research group - Good Lots of examples
- Bad Language is not always as good as it could
be definitions are sometimes somewhat "blurry",
maybe too many abbreviations used - Probably not very "break-through" ideas, national
DB conference - Remember this is from year 2000 - rather new!
Recommended
CrystalGraphics Presentations





























